两位助教早已先行落座。男助教 Kirk 是个中年白人,灰白的头发,戴着黑框眼镜,画风很像 Tim Cook。女助教是一位印度裔,好像叫 Assha。待大家都找到自己的位置并落座,Goenka 诵经的声音响起。Vipassana 虽然是线下课,但却是函授—内观的内容都是通过一位叫 Goenka 的老哥的语音和视频教授的。
Goenka 诵经的风格我一直 get 不太到。信佛或者很喜欢的人可能从他的吟唱中听出了悲悯,听出了博爱和美好的祝愿。我只听到了他的气泡音。气泡音多到了在第五天还不是第六天我总结“要成为宗教/玄学领袖必须有的个人特质”时气泡音被我列为其中一条。低沉的嗓音加上气泡音,在空旷的大厅中混响,确实能够带来一定的庄严感和神圣感。除此之外,Goenka 的诵经吟唱总体上而言我觉得很稳定。有些经文他在之后很多天都会重复。能听得出来每次都是实录不是播放同一段(因为有些许情绪的不同),但总体来说一致性保持的很好,也能清晰的听到他在唱什么(偶尔也有卡痰咳嗽出现)。比雍和宫法物开光那位不知道高到哪里去了。这里给大家播一下我最喜欢的选段:
继续实践下去果真有奇妙的感悟。我发现当我关注呼吸时我的感受的时候,我就仿佛在进行一场精神世界里的潜水。潜水和观呼吸真的有许多相似之处:最直白浅显的,便是呼吸本身的重要性。潜水靠呼吸调节浮力,而内观时呼吸则是此时此刻唯一真实的东西。潜水和内观也都是很个人的互动。极少的与他人的互动。在专注时,整个环境里可以只有你自己。潜水时,你只能看鱼,不能摸它。内观时,你只能看自己的感受,不去改变它。潜水,护目镜一带,满眼望去是蓝色的。内观时,眼睛一闭,主题色是黑色的。当我把这两件事串联在一起,原本无聊和 get 不到的事情也变得有趣和有意义。内观楼成为了一个潜水艇,我们百人一起从艇里游出来,呼吸之间,感受着水流的韵律,等待着不知道什么样的鱼会出现让我们观察。
身体扫描对我来说的第一大问题就是看不见。我的身体是空的。就像是有个洞一样。譬如我专注在我的前胸,甚至开始想象我的前胸(按理说不应该有任何画面的具象,应该要把全部精力用于感受),我会什么都感觉不到,仿佛我没有胸。在跟助教的交流后听起来这是很普遍的一个问题,简单来说就是观的还不够多。按照 Vipassana 的理论,身上的每一寸每时每刻都有着 sensation 在发生(甚至身体里也是),所以观不到并不是没有 sensation,而只是 mind 还不够 sharp,或者观察的还不够认真。有一些小的诀窍可以帮助大家找到感觉,比如尝试观察衣服接触皮肤的感觉,但对我来说,即使这个也非常微弱,而且没有接触的部分依旧没有觉知。这个问题在未来六天的内观中有所好转,但直到最后我也依旧有部分位置看不到。相比较而言,我的头皮,脸,腿就很好看。好看到可以指哪儿打哪儿。就像镭射一样,我聚焦到任意一个点上,都可以觉知到那一个点此时此刻的感受。
身体扫描的另一大难点就是打坐不换姿势所带来的疼痛。从第四天起我们开始践行 Adhitthana,在每天的三次一小时集体冥想时尽量不改变姿势。我一开始尝试的半莲花不仅不够优雅,而且会背部酸痛。后来我又开始尝试跪坐:在两腿之间垫三个垫子,两腿叉开跪坐在垫子上。尝试之后发现背会不自觉的挺直,非常舒爽。唯一的问题就是膝盖会痛腿会麻。尝试了两天后我觉得没有完美的冥想姿势,腿腰膝盖总要至少疼一个。也是从这一天开始越来越多人换成了用椅子(男生这边一开始可能只有三四个人,最后有十几个人都坐在椅子上内观了。之后内观室侧面和后面的墙边都摆满了椅子)不过我决定咬牙坚持下,毕竟想体验最原汁原味的内观。而且 Christopher 和 Carl 甚至从一开始就一动不动。我不能输。
四月,我们创业公司在融资。那时候觉得有一万件事需要我的注意力。要平衡生活工作、朋友社交和生活独处,感觉 everyone wants a little piece of me。我只觉得累,但没有觉得特别累。直到某日坐在地铁上,我就开始掉眼泪。掉眼泪不是哭,我没有情绪的感觉,首先冒出来的感觉是“哇为什么我突然开始流眼泪,好神奇”。然后是“车厢里别的人看我流眼泪会不会觉得很奇怪”。但我确实那一个瞬间感觉不到难受。流眼泪就像流鼻涕一样。不是被某个情绪戳中了,就是满了溢出来了。停不下来。
后面又有一日,从一大早等某家风投下午给我们打的 decision call。有些悲观,觉得还要约个电话不直接发 term sheet 估计是凉凉了。但又想,之前的许多 signal 还比较正面,而且要拒的话发个邮件就好了,没必要约个电话。然后就开始干呕,恶心想吐。第一反应是:“你又怎么了。等高考成绩都没有这么大反应,一通电话至于吗?”第二反应是:“记得在知乎还不是哪儿看到说人的任何情绪到了极端都是想吐。”
其实我还挺喜欢 NS 的。喜欢那种可以理所应当目中无人的感觉。本来跟陌生人对视就有些尴尬,现在可以正大光明的移走视线或者干脆看地,即使面对面走来也可以不必(不能)点头示意 say hi,很爽。我再次确信自己骨子里是个 I 人。又想到自己上学时候很喜欢上课接下茬。人是会变的。Anicca,Anicca,Anicca。
另一个里程碑是心态上接受看不到的事实。在努力了几天之后前胸后背的一些位置依旧是空白的,没有感知。我第八天晚上洗大澡的时候特地把自己摸了一遍,想记住这种触感,可依旧没用。Goenka 说如果感受不到 sensation,就停留一分钟,停留一分钟依旧感受不到就移动到下一个区域,没有关系的。接受现在的状态就是感受不到。See things as is, not as you would like them to be. 不要产生厌烦焦虑或者难过的心情。有这些反应也会产生 Saṅkhārā,就失去了我们内观的意义。我觉得这可能是最底层的与自己的和解。和解首先需要有能觉知现实的能力。其次要有能够接受现实的心态。最后要有能够承认自己能力不足的勇气并平和的面对它。我觉得当我可以接受我就是看不到我的一些部位时,我好像更爱我自己了。在内观的修行上,人与人的攀比本就没有意义。那我骗我自己或不能去接受这是一个需要时间和努力的过程就更没有意义。就像从经验层面上接受了无常一样,我也从(内观的角度上)更底层与自己和解了。
最先开始的是眼神交流。大家的视线不再避让,四目相接会点头微笑示意。我还是社恐,不知道该在哪儿呆着,跟谁说话,自己先小声哼哼了几声,感觉自己的声音和印象中的声音不大一样。太久不说话好像声带还不习惯震动。
我一头扎进了树林里。没走几步路就看到了 Carl 和 Sam 在聊天。他们看到我也跟我打招呼,我的出关第一句话很可惜不是 hello world 而是 hey what’s up guys。
我还在想他们怎么这么快就熟络起来,聊起天才发现,Carl 和 Sam 本来就认识,相约一起来内观营。Carl 说他们是高中同学。我还有些意外,因为 Carl 很明显的美式口音,Sam 则是英国腔。原来他们之前都在迪拜读高中,后来 Carl 回了加拿大,现在又来了英国,住在 Sam 附近的城市(利物浦附近)。
我们三人一起在树林里走了几圈,又在草地边的长椅坐下。我们从过去九天的冥想体验聊起,什么时候觉得通了,什么时候又觉得最难熬。哪天最想破戒,有没有想要离开的冲动。Sam 说他第四天感觉已经是极限了,非常想逃跑,可是是 Carl 开车带他来的,他还得先从 Carl 那里把车钥匙偷到,感觉太过麻烦只得就此作罢。我们都哈哈大笑。我问他们如果认识彼此又不能说话这几天会不会很难熬,Carl 说他感觉还好,毕竟在内观室并不挨着(中间隔一个人),回到房间大家都有帘子隔着,不刻意地话其实可以一天都不跟对方接触。(我真的完全没有看出来他们认识,比如吃饭的时候也没有印象他们总是坐在一起或者会对视/窃窃私语)。
Carl 和 Sam 感觉是两个 E 人。Sam 我并不意外,举手投足中真的都和我的前同事 Jordan 很像。Carl 比我想象中也健谈许多,高冷学霸光环破灭了。
另一位学霸 Christopher 的光环也小小破灭。我本以为他会是六根清净的人设。第九天看到他约了跟老师的 1 对 1,我都在想是不是他在问如果想要全职修行、剃发为僧的步骤是怎样的。结果 Christopher 是个甜甜恋爱人设。他是跟他女朋友来的,一个印度裔的小姐姐。他俩自从 Noble Silence 解除可以在规定的区域内男女聊天,就一直黏在一起对话。也没看 Christopher 跟别人说话,我也不好意思去当电灯泡跟我的邻居 say hi。
午饭时 Takoyaki 坐到我旁边,我们也聊了天。我先是夸了他很认真,说我有几天早晨四点半到内观房时发现他已经在了,后来累了想回房休息一下再继续,他还一动不动地披着毯子在那里打坐。他用非常日本人地谦虚感回复我说他觉得自己冥想的很差,一点都不认真。原来 T 桑十几年前就在东京上过一次十天的内观课了,多年之后再来英国,感觉之前学的都忘得差不多了。我问他是什么让他想要再来一次内观营。他说他最近被谢菲尔德大学的哲学博士项目录取了,入学前正好有一些时间。他本身也是对于 morality 和 mind 很感兴趣,觉得在哲学的理论学习之外,冥想也是一种实践。他还跟我分享了关于开小差的科学/哲学理解,为什么人会 mind wondering,mind wondering 的不同阶段等等,挺有意思。
后面还有好几个人主动来找我搭话。原来不仅我在偷偷观察别人。很多人也在偷偷观察我。有一个叫 Vivek 印度小哥看到了我有一日穿着我前司的衣服,最后一日特别来找我聊几句,他在 London 的 Meta 做 engineer manager,也是之前从湾区到了纽约又到了伦敦。人听上去很厉害,之前也是搞竞赛然后肉身翻墙直接在印度被招到 Facebook MPK。我本来想秀一下我的人脉,结果耐不住 Meta 实在太大,似乎没有共友。只得相约次日能用手机之后加一下好友,靠社交网络帮我挽尊。
我还认识了 Ed,是摸鱼小哥的室友。Ed 是一个 film location scout,我之前听都没听过的职业。他做的事就是帮电影导演选电影拍摄地,然后拍摄样张,再 pitch 给导演团队。如果选中了就会负责当地的联络事宜:拿到拍摄许可,安排整个团队的车停在哪里,如果没有网络要提前过去把网络设置好,如果需要还得联系政府设好路障,等等等等。听他讲他的工作,感觉就是一个有超多体力活+沟通需求的开放世界解谜游戏:毕竟电影+场地的不同就会使得每一个项目都有着独特的挑战,很难套公式。Ed 也不是科班出身,本身读国际关系的他,因缘际遇走上这条路之前,也去非洲当过 builder,欧洲当过英语老师,在学校做过 RA,在伦敦当过公务员,但最后公务员的官僚作风让他觉得作为一个纳税人他的钱就被扔进一个如此低效地系统实在令人痛心疾首,于是半年后就果断裸辞,然后拥抱对电影和旅游的喜欢,走上了 location scout 的路。听他讲这种项目制的生活状态(如果想闲一点可以一年只工作半年,想忙一点可以项目不停轮轴转),讲跟各种有名的导演和演员打交道(他帮魔戒选了址!)谁很 nice 谁耍大牌,还有看到自己名字出现在电影结尾 credit 的名单上时的感受,感觉对我来说就是另一个世界。我最后一天还在愁怎么回伦敦,因为星期日早上七点闭营而星期日第一班公交车要到十一点才有。我随口问了句 Ed 他怎么来的,Ed 说他开车来的,然后问我需不需要搭他车回去。当时又感觉到世界上有许多爱和善意,我和 Ed 萍水相逢,第十天聊天前我甚至没有注意到他。后来我跟 Ed 相约他年底从巴西玩回来后伦敦相见,请他喝酒 🍺 :)
下午在食堂外的空地上,大家继续围成一个圈聊天。course manager Patrick 和 Will 也加入我们聊天。一开始我以为 course manager 都很高冷,要维持管理者的那种严肃气质。但后来发现他们也就是 server(志愿者服务人员)团队里的一员,和厨房里做饭的 server 没有差别。我问 Will 那为什么你会是 course manager,他说他也不知道为什么,这是他第二次做 server,上一次做完这边的总负责人就说 Will 你下一次再来去试试做 course manager 吧,正巧 Patrick 是一个比较有经验的 course manager,于是就让他们俩搭伙。我问 Will 你上一次做 server 是什么职务,他一笑说我是主厨!我很诧异,问他说你是不是很会做饭,所以申请的时候他们就把你放在了主厨的位置上,他说完全不是,他一点都不会做饭,不过没有关系,这个冥想营的运动机制就是规范化流程,所有人都按照列表办事,怎么洗蔬菜怎么切菜怎么做饭全都有傻瓜指引,这就是这么多年办营留下来的经验总结。“就连 course manager 也是一样的”,Patrick 说,并从他和 Will 都随身带着的小挎包里拿出一张纸,上面写着几点要在哪儿做什么。原来这就是依靠(可能毫无经验的)志愿者也能有效运作的秘密!
最后一个充实的原因是我有了比较大块的思考时间。我是从我的同事John那里得到的灵感。他写了一篇博文讲述了他去年夏天休假两个月去加州的沙漠买地造房子的故事,非常酷。其中有一段他讲到他有24小时什么都不干,就在想,然后用纸笔记下来他的明天、6周、4年和10年的人生目标、职场规划、造的房子的后续计划、疯狂的想法等等。能够在繁忙的工作和生活中留白,去思考,去计划,真的很重要。我这次也创造了一个词,在城市公园中闲逛,同时去思考自己是谁,要什么,是为“wonder and ponder”——身体和灵魂同时在路上。我这次也有一个Note写的都是我想了什么,里面有:
这个世界上发生的事,如果需要我去主动了解,它就与我无关。上周倘若我没有闭关,估计第一时间就会知道诸如国内Tesla Model Y降价,吴亦凡的新瓜,BOSS直聘也被下架等等家长里短的八卦。但当我闭关回来,很多这些昔日热点早就不再是热点——他们的生鲜期甚至还没有几十个小时。可能闭关回来后我唯一有些关心的新闻就是任天堂突然公布Switch OLED新机型,然而就是这个也只是让我这个买游戏多过玩游戏的人听一耳朵图一乐。借我室友的话,可能我唯一需要关心的新闻,就是譬如伦敦变成僵尸城这种会影响我回程的事情,然而这种程度的事,我相信即使我不看手机也总有途径能够知道。同理,我相信如果有什么需要我的紧急且重要的事,对方也总能想办法找到我的。也因此,所有需要我去主动了解的事,它归根结底没有那么重要、没有那么相关。
现在我在tray 3(第三周)。其实我开始正畸的时间还蛮巧的,刚好赶上Work from Home。这使得摘戴牙套,包括吃东西后清洁等等都方便很多。而且因为我没有买什么零食/饮料,也不存在在办公室有很多零食诱惑,没事就想去拿点零嘴(然后就要摘牙套)的问题。所以目前体验挺不错的,很快就习惯了,没有给生活带来什么不方便。
二是让自己fall into the pit of success (成功之坑)。简单来说,就是要让对于最懒的我来说,最自然的事情就是能让我成功的事情。比如说,我在工作桌上总是放一杯1L的水,这样我下意识的就会开始喝水;再比如说,我买酸奶只会买Fage 0%的希腊酸奶,这样我想喝酸奶的时候就只有无糖酸奶的选项。每天已经很忙很累的我,不想自己再把自制力用到这些事情上,所以就让环境自然带我到“成功之坑”里好了。
然而我的弱点不仅仅是那些我可以去学会和改进的事情,还有很多我不能控制的事情,比如H1B工作抽签。我很讨厌这种out of my control的事情,因为我什么都做不了只能任命。这让我觉得我更脆弱了。我的人生轨迹,可以轻易的被几十行或者几百行的代码所左右。这种黑客帝国一般的设定,第一次离我这么近。
我很多计划都被一个抽签的结果打乱了——小到买沙发,养狗,看房……大到工作,朋友圈,自己会在哪个国家生活,全都contingent on 3月31号的一封邮件。
其实说来,这种人生转折点也不是第一次经历了——被少儿班录取,高考,本科交换,研究生录取,找实习,找工作……现在回看,connect those dots,也是这一个一个转折点让我成为了今天的我。可能H1B和这些节点唯一的区别就是我的主观能动性并没有什么用吧。It’s purely a probability game.
Bay Area是一个奇妙的地方。一千个人眼里有一千个湾区,我眼里的湾区是一个大大的泡泡。我在这里被保护的很好——工作日饭会从天上掉下来,我拿着脱离开湾区的context让人艳羡的工资,工作两年开着一辆Tesla,一个人住着studio。这个泡泡不真实到了因为疫情大家都开始在家办公后,组里讨论在家办公后有何感受,最多人赞同的就是”吃饭难“。一群二三十岁的成年人,因为饭不再会从天上掉下来,而发着愁。
]]>Alan Duanduanyanl97@gmail.comJoining Robinhood! (in Chinese)2017-12-27T00:00:00+00:002017-12-27T00:00:00+00:00https://yanlin-duan.github.io/career/joiningrobinhood1
至于小伙伴嘛,三年前一起上课认识的女生E,三年后又在Airbnb一起实习,也是非常巧的再遇了。见面后聊起曾经一起做的recursion的作业,当时被Python函数的默认变量是mutable object所造成的各种bug,现在还是记忆犹新。同一个互帮互助小组的女生H,一年前正式成为了15-112的助教。在Kosbie给她发邮件说我来CMU了之后五分钟,她就冲到了办公室跟我say hi拥抱。即将入职Morgan Stanley IBD的她,说能够0基础survive 15-112,之后辅修计算机,甚至成为15-112的助教,都是因为我当时在互帮互助小组给她的鼓励和帮助。当她说出那句“You are such a great mentor. I won’t be at this place without you”的时候我真的心头一暖。还有男生C,这个夏天在亚麻实习,享受着西雅图的生活甚是愉快。这次我来匹兹堡也是热情款待,让我倍感温暖——说到底,我们可是一起写过俄罗斯方块的交情啊!
当然,最巧的还是我那个学期15-112的Assistant Head TA是我高中的学姐。每次她在办公室,Kosbie都会说她是”Gates楼里最聪明的女生”。三年前印象最深的就是我问学姐为什么选择去Dropbox做全职,我期待着听到比如职场发展好啦,工作有趣啦等等的答案。然而学姐想了一会儿,说:
当然,看食堂选offer这样的操作,也是半认真半讲笑的。在我拿到几个offer不知所措的时候,我去问过学姐该怎么选择。她说,有些公司你去面试,跟你的面试官聊完,你就知道你不会想去那里工作。而有些公司,你一聊就会发现,人很聪明很有趣,跟他们共事也会学到很多。对于这点我不能同意更多。可能在尚未确定着落的时候,所谓“面试是双向选择”这样的说法中听不中用。但一旦心态摆正,想清楚你与公司的关系就是公司花钱买你的时间,谁都不欠谁,这种时候,你的面试官是否聪明,是否专业,是否让你觉得跟他们每天在一起会很开心,就非常重要了。这也是我在最终决定自己第一份工作去哪里时,一个重要的考量:我抓住每次跟人聊天的机会,去了解我的面试官,去了解公司的商业模型,了解工程师文化。跟每个面试官的接触,我都会注意:我讲了一个之前的做的项目,ta是不是很快就能找到其中的难点/有趣的点,然后一起讨论?我有题目做不出来的时候,ta是如何引导我的?如果我提出什么ta可能之前没想过或没见过的方法,ta是强行让我做回ta熟悉的方法,还是能很快给出反例/给我机会去证明新方法也可行?聊到公司的时候,ta是只会泛泛地说“一切都好”,还是可以很走心的举出例子讲出故事来证明“It’s really a great place to work at”?问到公司有什么不好/待改进的地方的时候,ta能不能诚恳的指出目前的问题和解决的办法?我觉得只有用心经营自己的职场发展和真正关心公司的人才会认真思考并能够回答这些问题,而我也希望能成为这样的人。
因为我全职面试是抱着寻找global optimum的目标,所以我选择面试下去的九家公司都属于我还比较有兴趣,也有朋友推荐的公司。很开心的是,自己感兴趣的这些公司的面试体验总的来说都很不错,考察的内容也很全面。除了数据结构和算法,有不少的公司也会问new grad系统设计(因为自己之前在面Asana实习的时候在这点上吃过亏,所以特别准备了一下;Airbnb的实习经历也给了这方面很多帮助)。其他还有被问到的包括OS(特别是multi-threading),Computer Network & Web 101(其实就是What happens after you type in an URL in a browser and hit enter),Front-end engineering(写Javascript)等。当然闲聊中根据我上过的课以及面试官的背景,我们就天南地北扯很多了:聊过我compiler的课是怎么用OCaml实现一个Rust-like语言的memory safety feature的;聊过我在15-112做的project是如何写爬虫parse data,如何用PyQt做前端,如何做data persistance的;聊过我正在上的某门课的某一个project用A*替代Dijkstra Algorithm的可行性的;聊我在Airbnb做project是如何遇到了一个React ref和lifecycle相关的issue而被坑的……总之放在简历上的东西,就要准备好用各种姿势花式去聊。当然,如果你所有项目都是认真做的,聊这些应该是非常自然,甚至很享受的一件事吧。(毕竟有人对你做过的东西感兴趣,哈哈)
Talk when you code。这个比较因人而异,我个人喜欢边说边写代码。这个比较类似于“小黄鸭debug法”:当你把自己想写的code一边写一边说出来的时候,你就更不容易犯typo/逻辑混乱,面试官也可以知道你的思考过程和进度,在有问题的时候提早“提醒”你,防患于未然。
对细节敏感。有一些地方是非常容易犯错的:index的计算,for loop的开始与截止(off-by-1),while loop的条件,if 多个条件是AND还是OR,recursion函数的返回值和base case等等。写到这些地方的时候我都会本能的放慢,仔细想清楚。如果一时想不清楚我也会跟面试官说“I may be off-by-one here. Let me finish first and we can come back to figure this out.”
Behavioral (行为面)的话,我经常遇到的问题就包括:
Why us?
What are you passionate about?
Why web engineering / Why product engineering?
Why do you switch from business to CS?
Among our core values, which one do you agree the most/least?
What are you looking for in your first job?
What’s your career goal?
遇到这类问题,其实我觉得真的就是那句话:“少一点套路,多一点真诚”。如果你期待一个面试官在一个小时内从不认识到你到strongly vouch for you,那你最好能够让ta了解你,而透过这些问题去讲述你的故事就是最好的方式。比如我对education一直都很有热情(这也与我在15-112所受到的改变人生的教育极有关系),所以即使是一个FinTech公司在问我What are you passionate about的时候,我也坦言教育之于我的意义,而我一直作为社会教育资源的受益者,是如何通过做助教,帮助他人准备面试,回答大家关于计算机相关的问题甚至参加Girls who code的公益活动去回馈社会的。因为这就是真实的我,所以我讲的时候就很具体,很走心,也就更打动人。当然,这样做的话就一定要准备好如何回答“那你对教育行业有这么浓厚的热情,为什么要申请我们公司呢?”这个问题 :)
我觉得Behavioral对于国际学生最大的瓶颈可能还是在于语言等因素的限制,自己有话却说不出来吧。这就让我很欣慰自己本科在香港四年,不说其他,但至少还是学到了如何去communicate my idea和present myself的。事实证明这也在我这次找工帮助很大。所以除了“硬技术”,“软实力”也很重要啊!
那天上午我第一次走进15-112的教室。我从没去过那么大的阶梯教室。我坐在不高不低的位置,懵懵懂懂听了一整节课。我以为第一节课大概就是做一做intro,教教print Hello world,一个多小时的课上半个小时也就差不多了。没想到第一节课就这么intense。print Hello World真的只教了30秒。对,30秒。第一节课,除了所有logistic & admin stuff,我们就讲了input, output, import modules, functions, return v.s. print, different types of error, variable scope…. 我记得特别清楚,当时有个同学举手问“is Python a compiled language or an interpreted language?” ,我听到的就是”is Python a bla or a bla?”,真的一脸懵逼,心想他们在说什么“鸟语”。我这个大三的“好学生”从来没有听一门课的第一节课就这么吃力过,更别提是面向大一新生的课。
Kosbie问我,“Why do you want to take this class?” (你为什么想上这门课?)
我说,“Because I want to learn some programming.” (因为我想学一些编程。)
“If you want to learn some programming, you should go take 15-110. It’s less intense, and you may find it more fun.” (如果你只是想学一些编程的话,去上15-110吧。那个课节奏更慢些,你可能会觉得更好玩。)
”If 15-110 is for learning some programming, what is this class for?” (那如果15-110是教一些编程的话,这节课教什么呢?)
“You know, At the end of this 15-week class, students will work on an individual term project. People get Microsoft internship with it.” (在这个课上,上完这15周的课你要做一个单人的编程项目。有学生用这个项目拿到了微软的实习。)
二,跟面试官聊完之后,我仿佛见到了很多个“我”。大家对于做一个好的product都很有热情;工程师也很重视产品设计和用户研究;而且聊到很多问题的时候都属于双方越聊越high型。聊到激动的时候,我就直接打开airbnb的网站,给他们看哪块是我做的,我是怎么做的;或者在白板上写写画画,讲system或product的design。至于coding的部分,Robinhood也是不同于其他很多公司。问题虽不难,但要求却是要Pythonic code that can check into the production code base。我很喜欢面试官问的一针见血的问题,有些时候也让我看到了自己的思维盲点和代码方面很多值得提升的地方:我的面试官们简直就是我希望自己在几年后成为的样子。
感谢Rachel from Asana和Vasusen from Coursera。你们都是我特别特别欣赏的manager & engineer。跟你们的聊天总是特别的有收获。没能加入你们的团队是我的遗憾。希望可以keep in touch!
感谢Robinhood的面试官们选择了我。Special thanks to Hongxia。以后多多指教啦!
感谢Yuyang学姐,Max Zhou还有易姐姐给我很多找工作+职场相关的建议!
感谢温总邀请我加入脑力+体力共同运动的健身小分队!各位健身达人带我举铁,我帮大家回答关于CS的各种问题,也算是”friends with benefit”了XD 谢谢你们让我两个月瘦了五公斤(希望不是累的)!
感谢朱总实力提供三番住宿!
感谢陈总实力提供匹兹堡住宿!
感谢戎姐在我东西海岸飞到快go die的时候carry了我的project们!
感谢我的粑粑麻麻支持我的决定!
感谢所有读到这里的你们 :)
]]>Alan Duanduanyanl97@gmail.comMy Review Note for Applied Machine Learning (Second Half)2017-04-29T00:00:00+00:002017-04-29T00:00:00+00:00https://yanlin-duan.github.io/machine%20learning/cheatsheetappliedMLpart2
Why this post
This semester I am taking Applied Machine Learning with Andreas Mueller. It’s a great class focusing on the practical side of machine learning.
I received many positive feedbacks for my review note of the first half of the class. I am therefore motivated to continue working on a similar post for the second half. Again, I am posting my notes on my blog so it can benefit more people, no matter he/she is in the class or not :)
Supplemental material of An Introduction to Machine Learning with Python by Andreas C. Müller and Sarah Guido (O’Reilly). Copyright 2017 Sarah Guido and Andreas Müller, 978-1-449-36941-5.
Care has been taken to avoid copyrighted contents as much as possible, and give citation wherever is proper.
Model Evaluation Metrics
Classification
Why do we need precision, recall and f-score
It is very natural to evaluate the performance of a model by looking at its accuracy – meaning out of all testing data, how many we get correct (predict true when it should be true, and predict false when it should be false).
However, this measurement becomes less effective if the data is imbalanced – meaning we have way more data in one class compared to others. For example – if 99% of the data are labeled as 1, a model can simply “cheat” by always predicting 1 – a naive, trivial but high accuracy model. In those cases, we need better measurements, and that’s why we introduce precision and recall.
I have had a long time memorizing which one is which, and there are so many combinations between True Positive, False Positive, True Negative and False Negative so I almost always get confused. I found it’s actually easier if we take a step back and first intuitively understand the word “precision” and “recall” (yes, the name is not a random one!)
When we say precision, we are talking about how precise you are. For example, if I am searching something on Google, I will say the precision is high when out of everything Google returns to me, I found most of them relevant to what I want to search for.
This means, I am measuring the proportion of correct search results (True positive) over everything Google predicts to be “what I want” (True positive and False positive).
For recall, I find it easier to understand it in an “ecology” context – in ecology, there is a method called “mark and recapture” where a portion of the population of, say, an insect is captured, marked and released (we remember how many we marked). Later, another portion is captured. We are now interested in out of all the marked insects, how much do we recall.
Back to machine learning, this naturally translates to the proportion of “recaptured and marked ones” (true positive) over all marked insects (true positive + false negative, i.e. those mark insects we recapture + fail to recapture).
Sanity Check time: if this review note is to predict topics covered in class, what should I include if I want to have a high precision? (Hint: count # of parameters in a neural network) How about a high recall?
As you can see from the sanity check question, it is not hard for models to achieve a perfect recall or a perfect precision alone. Therefore, we would like to summarize them – and that’s what f-score, the harmonic mean of precision and recall, is doing.
Other common tools
Precision-Recall Curve. Area under it is the average precision (ignoring some technical differences). Ideal curve –upper right.
Receiver operating characterisitics (ROC), which is FPR (\(FP/(FP+TN)\))v.s. TPR (recall). AUC is the area under the curve, which does not depend on threshold selection. AUC is always 0.5 for random prediction, regardless of whether the class is balanced. The AUC can be interpreted as evaluating the ranking of positive samples. Ideal curve – upper left.
Multi-class Classification Metrics
Confusion Matrix and classification report (note: support means number of data points (ground truth) in that class)
Micro-F1 (each data point to be equal weight) and Macro-F1 (each class to be equal weight)
Regression
Built-in standard metrics
\(R^2\): a standardized measure of degree of predictedness, or fit, in the sample. Easy to understand scale.
MSE: estimate the variance of residuals, or non-fit, in the population. Easy to relate to input
Mean Absolute Error, Median Absolute Error, Mean Absolute Percentage Error etc.
\(R^2\) is still the most commonly used one.
Clustering (supervised evaluation)
When evaluating clustering with the ground truth, note that labels do not matter – [0,1,0,1] is exactly the same as [1,0,1,0]. We should only look at partition.
Why can’t we use accuracy score
The problem in using accuracy in clustering problem is that it requires exactly match between the ground truth and the predicted label. However, the cluster labels themselves are meaningless – as mentioned above, we should only care about partition, not labels!
Contigency matrix
One tool we will use is contingency matrix. It is similar as confusion matrix, except that it does not have to square, and switching of rows/columns will not change the result.
Rand Index, Adjusted Rand Index, Normalized Mutual Information and Adjusted Mutual Information
Rand index measures the similarity between two clustering. The formula is \(RI(C_1,C_2) = \frac{a+b}{n \choose 2}\), where \(a\) is the number of pairs of points that are in the same set in both cluster \(C_1\) and \(C_2\), while $b$ is the number of pairs of points that are in different sets in $C_1$ and $C_2$. The denominator is just number of all possible pairs.
It can be intuitively understood if we view each pair as a data point, and treat this problem as using \(C_2\) to predict \(C_1\) (the ground truth). (Or the other way around, it’s symmetric).
We count the number of true positive (they are in the same cluster in \(C_1\), and \(C_2\) predicts that they are also in a same cluster), plus the number of true negative (they are not in the same cluster in \(C_1\), and \(C_2\) predicts that they are also not in a same cluster) Sounds familiar now? Yes, it is just an analogy of accuracy!
Sanity Check Question: What is R([0,1,0,1], [1,0,0,2])?
Rand Index always ranges between 0 and 1. The bigger the better.
Adjusted Rand Index (ARI) is introduced to ensure to have a value close to 0.0 for random labeling independently of the number of clusters and samples and exactly 1.0 when the clusterings are identical (up to a permutation). ARI penalizes too many clusters. ARI can become negative.
Note: ARI requires the knowledge of ground truth. Therefore, ARI is not a practical way to assess clustering algorithms like K-Means.
Furthermore, we have normalized mutual information (which penalizes overpatitions via entropy) and adjusted mutual information (adjust for chance, so any two random partitions have expected AMI of 0).
Clustering (unsupervised evaluation)
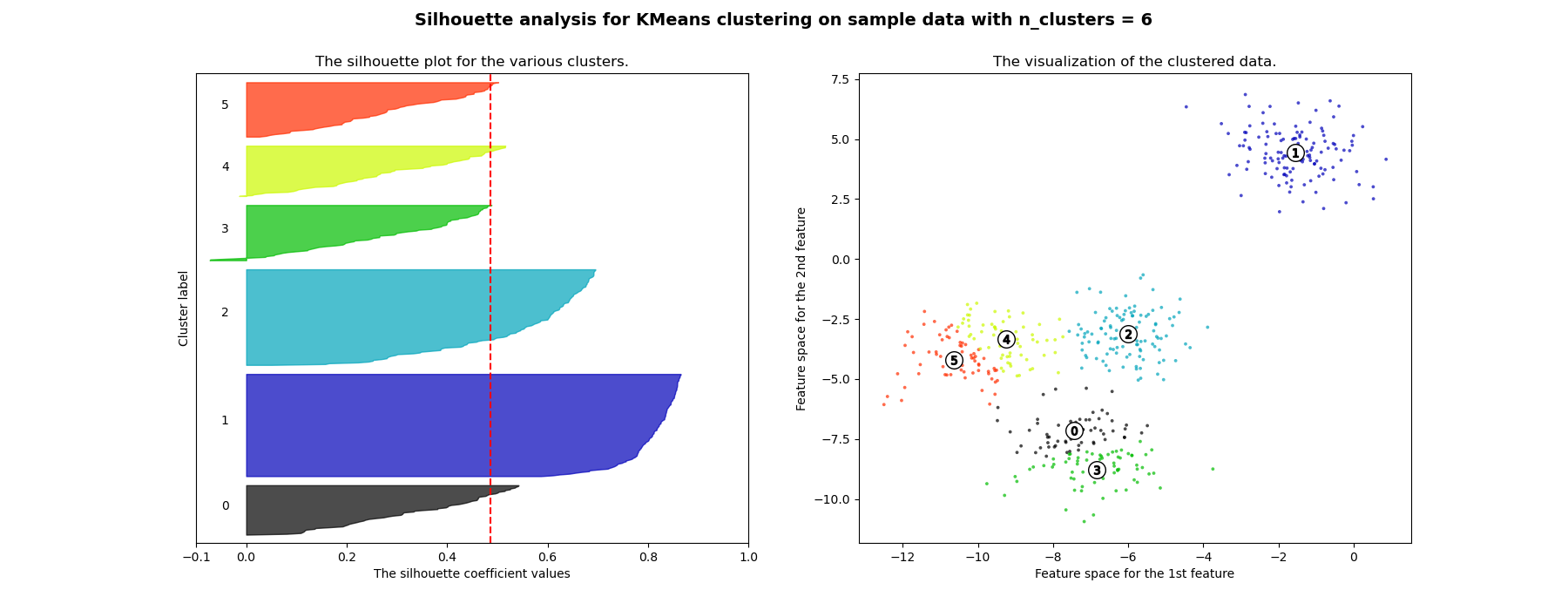
Silhouette Score
Formula:
For each sample, calculate \(s = \frac{b-a}{\max(a,b)}\), where \(a\) is mean distance to samples in same cluster, \(b\) is the mean distance to samples in nearest cluster.
For whole clustering, we average s over all samples.
This scoring prefers compact clusters (like K-means).
Rationale: we want to maximize the difference between \(b\) and \(a\), so that the result is decoupling and cohesion (sounds like object-oriented programming hah?)
Cons: While compact clusters are good, compactness doesn’t allow for complex shapes.
Sample code for choosing evaluation metrics in sklearn
# default scoring for classification is accuracy
scores_default=cross_val_score(SVC(),X,y)# providing scoring="accuracy" doesn't change the results
explicit_accuracy=cross_val_score(SVC(),X,y,scoring="accuracy")# using ROC AUC
roc_auc=cross_val_score(SVC(),X,digits.target==9,scoring="roc_auc")# Implement your own scoring function
deffew_support_vectors(est,X,y):acc=est.score(X,y)frac_sv=len(est.support_)/np.max(est.support_)# I just made this up, don't actually use this
returnacc/frac_svparam_grid={'C':np.logspace(-3,2,6)}grid=GridSearchCV(SVC(),param_grid=param_grid,cv=10,scoring=few_support_vectors)
Dimensionality Reduction
Linear, Unsupervised Transformation – PCA
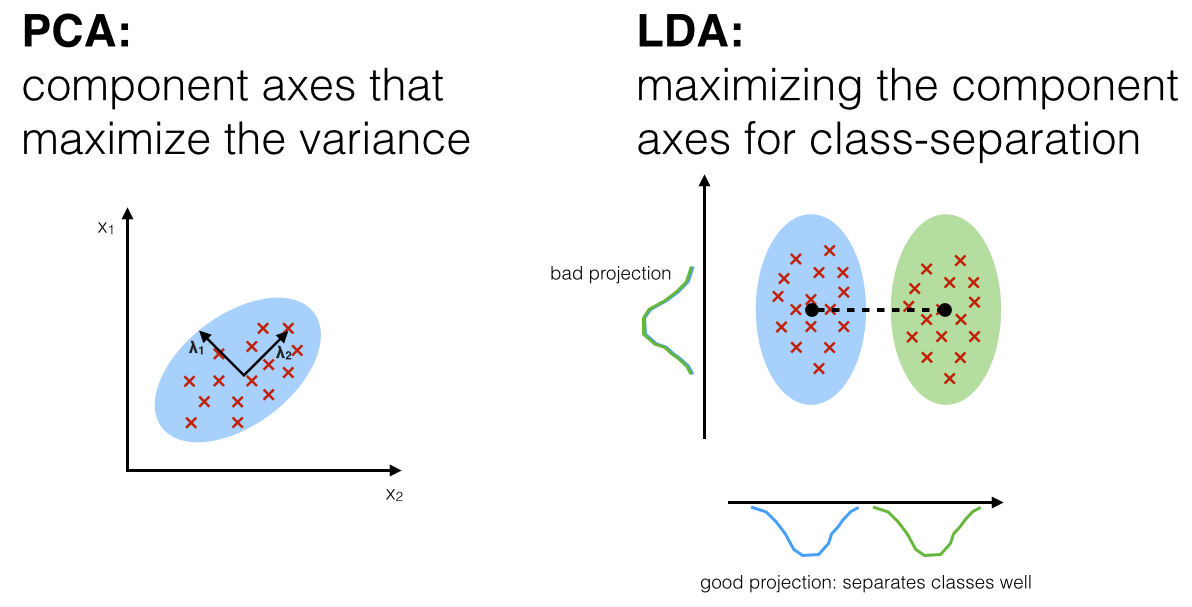
PCA rotates the dataset so that the rotated features are statistically uncorrelated. It first finds the direction of maximum variance, and then finds the direction that has maximum variance but at the same time is orthogonal to the first direction (thus making those two rotated features not correlated), so on and so forth.
When to use: PCA is commonly used for linear dimension reduction (select up to first k principal components), visualization of high-dimensional data (draw first v.s. second principal components), regularization and feature extraction (for example, comparing distance in pixel space does not really make sense; maybe using PCA space will perform better)
Whitening: rescale the principal components to have the same scale; Same as using StandardScaler after perfoming PCA.
Why PCA (in general) works
PCA finds uncorrelated components that maximizes the variance explained in the data. However, only when the data follows Gaussian distribution, zero correlation between components implies independence, as the first and second order statistics already captures all the information. This is not true for most of the other distributions.
Therefore, PCA ‘sort of’ makes an implicit assumption that data is drawn from Gaussian, and works the best when representing multivariate normally distributed data.
Important notes
PCA, compared to histograms or other tools, is used because it can capture the interactions between features.
Do scaling before performing PCA. Imagine one feature with very large scale. Without scaling, it’s guaranteed to be the first principal component!
PCA is unsupervised, so it does not use any class information.
PCA has no guarantee that the top k principal components are the dimensions that contains most information. High variance \(!=\) most information!
Max number of principal components min(n_samples, n_features).
Sign of the principal components does not mean anything.
There’s cancellation effects because of the negative components.
NMF stands for non-negative matrix factorization. It is similar to PCA in the sense that it is also a linear, unsupervised transformation. But instead of requiring each componenet to be orthogonal, we want the coefficients to be non-negative in NMF. Therefore, NMF only works to data where each feature is non-negative.
Pros:
NMF leads to more interpretable components than PCA
No cancellation effect like PCA
No sign ambiguity like in PCA
Can learn over-complete representation (components more than features) by asking for sparsity
Can be vised as a soft clustering
Traditional Nonnegative Matrix Factorization (NMF) is a linear and unsupervised algorithm. But there are novice ones that can extract non-linear features (http://ieeexplore.ieee.org/document/7396284/?reload=true)
Cons:
Only works on non-negative data
Can be slow on large datasets
Coefficients not orthogonal
Components in NMF are not ordered – all play an equal part (also can be a pro)
Number of components totally change the set of components.
Non-convex optimization; Randomness involved in initialization
Other matrix factorizations:
Sparse PCA: components orthogonal & sparse
ICA: independent components
Non-linear, unsupervised transformation - t-SNE
t-distributed stochastic neighbor embedding (t-SNE) is an algorithm in the category of manifold learning. The high level idea of t-SNE is that it will find a two-dimensional representation of the data such that if they are ‘similar’ in high-dimension, they will be ‘closer’ in the reduced 2D space. To put it in another way, it tries to preserve the neighborhood information.
How t-SNE works: it starts with a random embedding, and iteratively updates points to make close points close.
The usage for t-SNE is now more on data visualization.
Note
t-SNE does not support transforming new data, so no transform method in sklearn
Axes do not correspond to anything in the input space, so merely for visualization purpose.
To tune t-SNE, tune perplexity (low perplxity == only close neighbors) and early_exaggeration parameters, though the effects are usually minor.
Linear, supervised transformation – Linear Discriminant Analysis
Linear Discriminant Analysis is a “supervised” generative model that computes the directions (“linear discriminants”) that will maximize the separation between multiple classes. LDA assumes data to be drawn from Gaussian distributions (just as PCA, but for each class). It further assumes that features are statistically independent, and identical covariance matrices for every class.
LDA can be used both as a classifier and a dimensionality reduction techinique. The advantage is that it is a supervised model, and there’s no parameters to tune. It is also very fast since it only needs to compute means and invert covariance matrices (if number of features is way less than number of samples).
A variation is Quadratic Discriminant Analaysis, where basically each class will have separate covariance matrices.
Outlier detection
Elliptic Envelope
Assumption:
Data come from a known distribution (for example, Gaussian distribution).
Rationale:
Define the “shape” of the data, and can define outlying observations as observations which stand far enough from the fit shape.
Implementation:
estimate the inlier location and covariance in a robust way (i.e. whithout being influenced by outliers).
The Mahalanobis distances obtained from this estimate is then used to derive a measure of outlyingness.
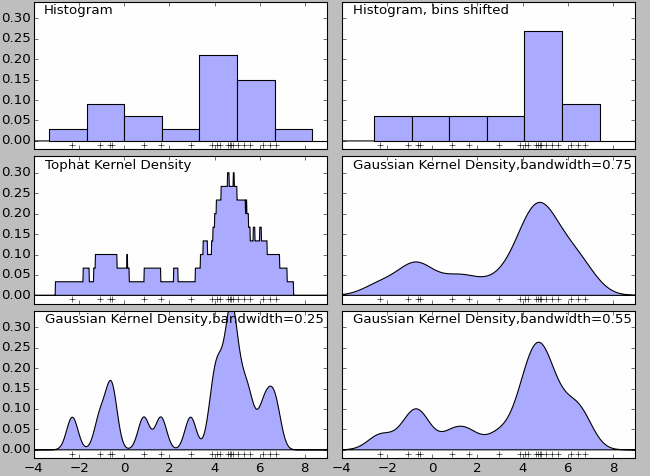
Kernel density estimation is a non-parametric density model. Essentially it is a natural extension of histogram. The density function for histogram is not smooth, and it can be largely affected by the width of the bin. Finally, histogram won’t work with high-dimension data – all these problems can be addressed by kernel density estimation.
One class SVM also uses Gaussian kernel to cover data. It requires the choice of a kernel and a scalar parameter to define a frontier. The RBF kernel is usually chosen as the kernel. The \(\nu\) parameter, also known as the margin of the One-Class SVM (percentage of training mistakes), corresponds to the probability of finding a new, but regular, observation outside the frontier.
Note:
As usual for SVM, do standard scaler before applying OneClassSVM is common practice.
The idea is to build a random tree and we expect that outliers are easier to isolate from the rest, since it is alone. Then we consider the path length for isolating each data point to determine who’s the outlier.
Normalizing path length
\[c(n) = 2H(n-1) - (2(n-1)/n)\]
\(s(x,n) = 2^{-\frac{E(h(x))}{c(n)}}\), where \(h\) is the depth of the tree.
s close to 1 meaning it is likely to be outlier.
Building the forest
Subsample dataset for each tree
Default sample size of 256 works surprisingly well
Stop growing tree at depth \(\log_2{n}\) –- so 8 No bootstrapping usually
The more trees the better (default is 100 trees)
Need to specify contamination rate (float in 0 to 0.5), default 0.1.
y_pred=lr.predict_proba(X_test)[:,1]>.85# change threshold to 0.85
Sanity check question: for the above code, would you expect the precision of predicting positive (class 1) to increase or decrease? How about recall? How about support?
Sampling approaches
Random undersampling
Drop data from the majority class randomly, until balanced.
Pros: very fast training, really good for large datasets
Instead of repeating samples, we can just re-weight the loss function. It has the same effect as over-sampling (though not random), but not as expensive and time consuming.
Random resampling for each model, and then ensemble them.
Pros: As cheap as undersampling, but much better results
Cons: Not easy to do right now with sklearn and imblearn
# Code for Easy Ensemble
probs=[]foriinrange(n_estimators):est=make_pipe(RandomUnderSampler(),DecisionTreeRegressor(random_state=i))est.fit(X_train,y_train)probs.append(est.predict_probab(X_test,y_test))pred=np.argmax(np.mean(probs,axis=0),axis=1)
Edited Nearest Neighbors
Remove all samples that are misclassified by KNN from training data (mode) or that have any point from other class as neighbor (all). Can be used to clean up outliers or boundary cases.
fromimblearn.under_samplingimportEditedNearestNeighbours# what? it's NearestNeighbours with u and n_neighbors without u
# @.@ Great API design...
enn=EditedNearestNeighbours(n_neighbor=5)X_train_enn,y_train_enn=enn.fit_sample(X_train,y_train)enn_mode=EditedNearestNeighbours(kind_sel="mode",n_neighbor=3)X_train_enn_mode,y_train=enn_mode.fit_sample(X_train,y_train)
Condensed Nearest Neighbors
Iteratively adds points to the data that are misclassified by KNN. Contrast to Edited Nearest Neighbors,this resampling method focuses on the boundaries.
fromimblearn.under_samplingimportCondensedNearestNeighbour# CNN is not convolutional neural net XD
cnn_pipe=make_imb_pipeline(CondensedNearestNeighbour(),LogisticRegressionCV())scores=cross_val_score(cnn_pipe,X_train,y_train,cv=10)
Synthetic Minority Oversampling Technique (SMOTE)
Add synthetic (artificial) interpolated data to minority class.
Algorithm
picking random neighbors from k neighbors.
pick a point on the line between those two uniformly.
repeat.
Pros: allows adding new interpolated samples, which works well in practice; There are many more advanced variants based on SMOTE.
Cons: leads to very large datasets (as it is doing oversampling), but can be mitigated by combining with undersampled data.
While cluster centers change:
– Assign each data point to it’s closest cluster center.
Recompute cluster centers as the mean of the assigned points.
Code:
km=KMeans(n_clusters=5,random_state=42)km.fit(X)print(km.cluster_centers_.shape)# km.labels_ is basically the predict
print(km.labels_shape)print(km.predict(X).shape)
Note:
Clusters are Voronoi-diagrams of centers, so always convex in space.
Cluster boundaries are always in the middle of the centers.
Cannot model covariance well.
Cannot ‘cluster’ complicated shape (say two-moons dataset, which I usually refer to as the dataset where two bananas “interleaving” together).
K-means performance relies on initialization. By default K-means in sklearn does 10 random restarts with different initializations.
When dataset is large, consider using random, in particular for MiniBatchKMeans.
k-means can also be used as fetaure extraction, where cluster membership is the new categorical feature and cluster distance is the continuous feature.
Agglomerative clustering
Algorithm:
Start with all points in their own cluster.
Greedily merge the two most similar clusters until reaching number of samples required.
Merging criteria:
Complete link (smallest maximum distance).
Average linkage (smallest average distance between all pairs in the clusters.
Single link (smallest minimum distance).
Ward (smallest increase in with-in cluster variance, which normally leads to more equally sized clusters).
Pros:
Can restrict to input “topology” given by any graph, for example neighborhood graph.
Fast with sparse connectivity.
Hierarchical clustering gives more holistic view, can help with picking the number of clusters.
Cons:
Some linkage criteria may lead to very imbalanced cluster sized (depending on the scenario, it can be a benefit!).
Sample is “core sample” if more than min_samples is within epsilon (“dense region”).
Start with a core sample.
Recursively walk neighbors that are core-samples and add to cluster.
Also add samples within epsilon that are not core samples (but don’t recurse)
If can’t reach any more points, pick another core sample, start new cluster.
Remaining points are labeled outliers.
Pros:
Can cluster well in complex custer shapes (two-moons would work!)
Can detect outliers
Cons:
Needs to adjust parameters (epsilon is hard to pick)
Mixture Models
(Gaussian) Mixture Model is a generative model, where we assume that the data is formed in a generating process.
Assumptions:
– Data is mixture of small number of known distributions (in GMM, it’s Gaussian). Each mixture component follows some other distribution (say, multinomial)
– Each mixture component distribution can be learned “simply”.
– Each point comes from one particular component.
EM algorithm:
This is a non-convex optimization problem, so gradient descent won’t work well.
Instead, sometimes local minimum is good enough, and we can get there through Expectation Maximization algorithm (EM)
Code:
fromsklearn.mixtureimportGassuainMixturegmm=GaussianMixture(n_components=3)gmm.fit(X)print(gmm.means_)# If X is of two dimension, returns 3 2D vectors
print(gmm.covariances_)# If X is of two dimension, returns 3 2x2 matrices
gmm.predict_proba(X)# For each data point, what is the probability of it being in each of the three classes?
print(gmm.score(X))# Compute the per-sample average log-likelihood of the given data X.
print(gmm.score_samples(X))# Compute the weighted log probabilities for each sample. Returns an array
Note:
In high dimensions, covariance=”full” might not work.
Initialization matters. Try restarting with different initializations.
It allows partial_fit, meaning you can evaluate the probability of a new point under a fitted model.
Bayesian Infinite Mixtures
Note:
Bayesian treatment adds priors on mixture coefficients and Gaussians, and can unselect components if they do not contribute, so it is possibly more robust.
Infinite mixtures replace Dirichlet prior over mixture coefficients by Dirichlet process, so it can automatically find number of components based on prior.
Use variational inference (as opposed to gibbs sampling).
n_clusters: For preprocessing, larger is often better; for exploratory analysis: the one that tells you the most about the data is the best.
Natural Language Processing
Generating features from text
The idea of bag of words is to tokenize the text, and then build a vocabulary over all documents, and finally do sparse matrix encoding on each token.
Code:
fromsklearn.feature_extraction.textimportCountVectorizervect=CountVectorizer()vect.fit(word)print(vect.get_feature_names())X=vect.transform(word)print(vect.inverse_transform(X)[0])# to see the bag
Tokenization
There are many options:
Specify token pattern: do you want numbers? single-letter words? punctuations? Specify by regex in CountVectorizer’s token_pattern.
Normalization (preprocessing)
Correct the spelling
Stemming: reduce to word stem (by a crude heuristic process that chops off the ends of words in the hope of achieving this goal correctly most of the time, and often includes the removal of derivational affixes)
Lemmatization: reduce words to stem using curated dictionary and context (properly with the use of a vocabulary and morphological analysis of words, normally aiming to remove inflectional endings only and to return the base or dictionary form of a word, which is known as the lemma)
Lowercase the words
Restricting the vocabulary (feature selection)
Stop words: exclude some common words using some built-in language-specific / context-specific dictionarys:
We think a certain character combination may be a good feature
Analyzer ‘char_wb’ creates character n-grams only from text inside word boundaries. It adds a space before and after each document and can generate larger vocabularies than ‘char’ sometimes. (See here)
Punctuation….!? (somewhat captured by char ngrams)
Sentiment words (good vs bad)
Domain specific features
Large scale text vectorization – hashing
When doing large scale text vectorization, instead of encoding each token in the vocabulary, we encode the hash value of each token in the vocabulary.
Pro:
Fast
Works for streaming data (can do one by one)
Low memory footprint
Collisions are not a problem for performance
Con:
Can’t interpret results
Hard to debug
Beyond Bag of Words
When doing bag of words, it is hard to capture the semantics of words. Also, synonymous words are not presented, and the representation of documents is very distributed. We are considering other ways to represent a document
Latent Semantic Analysis (LSA)
Reduce dimensionality of data.
Can’t use PCA: can’t subtract the mean (sparse data)
Instead of PCA: Just do SVD, truncate.
“Semantic” features, dense representation.
Easy to compute – convex optimization
fromsklearn.preprocessingimportMaxAbsScaler# To get rid of some dominating words in a lot of components
X_scaled=MaxAbsScaler().fit_transform(X_train)fromsklearn.decompositionimportTruncatedSVDlsa=TruncatedSVD(n_components=100)X_lsa=lsa.fit_transform(X_scaled)
Topic Models
We view each document as a mixture of topics. For example, this document can be viewed as a mixture of computer science, applied machine learning and review notes (really bad topic selection…)
We can do NMF for topic models, where we decompose the matrix (document x words) to H and W where H is topic proportions per document and W is topics.
We can also do LDA – Latent Dirichlet Allocation for topic modelling. LDA is a Bayesian graphical generative probabilistic model. The learning is done through probabilistic inference. This is a non-convex optimization and solving it can even be harder than mixture models.
Two solvers:
Gibbs sampling using MCMC: very accurate but very slow
Variational inference: faster, less accurate, championed by Prof. David Blei
Rule of thumbs for picking solver:
Less than 10k documents: use Gibbs sampling
Medium data: variational inference
Large data: Stochastic Variational Inference (which allows partial_fit for online learning)
Word embedding
Before we are embedding documents into a continuous, corpus-specific space. Another approach is to embed words in a general space. We want this embedding to preserve some properties: for example: two words that are semantically close should be closer in the mapped vector space.
For example: if we have three words: ape, human and intelligence. If we were using one-hot encoding, we would represent each as [1,0,0], [0,1,0] and [0,0,1], which is sparse and unnecessary (esp when we have A LOT OF WORDS!).
Word embedding may choose to represent them as [0,1], [0.4,0.9] and [1,0]. We have lower dimension, and we kind of preserve the semantics.
C-BOW stands for continuous bag-of-words. It tries to predict the word given its context. Prediction is done using a one-hidden-layer neural net, where the hidden layer corresponds to the size of the embedding vectors. The prediction is done using softmax. The model is learned using SGD sampling words and contexts from the training data.
Skip-gram
Skip-gram takes the word itself as input and predict the context given the word. You’re “skipping” the current word (and potentially a bit of the context) in your calculation and that’s why it is called skip-gram. The result can be more than one word depending on your skip window. Skip-gram is better for infrequent words than CBOW.
Wait… but why we are doing that?
We don’t really care about the result of CBOW or Skip-gram. Even if we do, the thing that relates to word embedding is that we hope the neural network will learn some useful representation of words in the hidden layer, and that, as a by-product, is what we want here.
Gensim
Gensim has multiple LDA implements and has great tools for analyzing topic models.
texts=[["good","luck","with","your","final"],["get","good","grade"]]fromgensimimportcorporadictionary=corpora.Dictionary(texts)corpus=[dictionary.doc2bow(text)fortextintexts]# To convert to sparse matrix
gensim.matutils.corpus2csc(corpus)# To convert from sparse matrix
sparse_corpus=gensim.matutils.Sparse2Corpus(X.T)# Tf-idf with gensim
tfidf=gensim.models.TfidfModel(corpus)# Tokenize the input using only words that appear in the vocabular used in the pre-trained model
vect2_w2v=CountVectorizer(vocabular=w.index2word).fit(text)# Examples with Gensim
w.most_similar(positive=["Germany","pizza"],negative=["Italy"],topn=3)
There may be stereotype / bias involved here!! (Ethics alert)
We can also do Doc-2-vec: where we add a vector for each paragraph / document, also randomly initialized. (another layer of complexity).
To infer for new paragraph: keep weights fixed, do stochastic gradient descent on the representation D, sampling context examples from this paragraph.
model=gensim.models.doc2vec.Doc2Vec(size=50,min_count=2,iter=55)model.build_vocab(train_corpus)model.train(train_corpus,total_examples=model.corpus_count)# To do encoding using doc2vec:
vectors=[model.infer_vector(train_corpus[doc_id].words)fordoc_idinrange(len(train_corpus))]
Neural networks is a non-linear model for both classification and regression. It works particularly well when the data set is large. It can basically learn any (continuous) functions. It is a non-convex optimization and is very slow to train (so need GPU resources) There are many variants on this and it is an active research field in machine learning.
General architecture
The general architecture of (vanilla) neural networks looks like this:
Where each layer contains many unit of neuron. For non-linearity, some common selections include: sigmoid, tanh (may get smoother boundaries in small datasets), relu (rectifying linear function, preferred for large network). For the last non-linearity though, we usually use a different function: identity for regression, and soft-max for classification.
Back-propagation
Back-propagation provides a way to compute the update of the weights easily. It combines chain rule and dynamic programming to systematically calculate partial derivatives layer by layer, starting from the last layer, without doing duplicate works.
Note that back-propagation itself does not optmize the weights of a neural network – It is gradient descent or other optimizer that optimizes the weight.
Solvers
The standard solvers include l-bfgs, newton and cg, but if computing gradients over whole dataset is expensive, it is better to use stochastic gradient descent, or minibatch update.
Similarly, constant step size \(\eta\) is not good. A better way is to adaptively learn \(\eta\) for each entry. There’s also adam, which uses a magic number for \(\eta\).
Rule of thumbs for picking solvers:
Small dataset: off the shelf like l-bfgs
Big dataset: adam
Have time & nerve: tune the schedule
Complexity control
Number of parameters
Regularization
Early stopping
Drop-out
Autodiff
Autodiff is the process to automatically calculate differentiation (usually when you are doing back propagation).
classarray(object):"""Simple Array object that support autodiff."""def__init__(self,value,name=None):self.value=valueifname:self.grad=lambdag:{name:g}def__add__(self,other):assertisinstance(other,int)ret=array(self.value+other)ret.grad=lambdag:self.grad(g)returnretdef__mul__(self,other):assertisinstance(other,array)ret=array(self.value*other.value)defgrad(g):x=self.grad(g*other.value)x.update(other.grad(g*self.value))returnxret.grad=gradreturnret# some examples
a=array(1,'a')b=array(2,'b')c=b*ad=c+1printd.valueprintd.grad(1)# Results
# 3
# {'a': 2, 'b': 1}
When you run d.grad(1), it recursively invokes the grad function of its inputs, backprops the gradient value back, and returns the gradient value of each input. It can be done because gradient calculation is sort of automatically ‘done’ while you perform addition and multiplication: we are keeping track of that computation and building up a graph of how to compute the gradient of it.
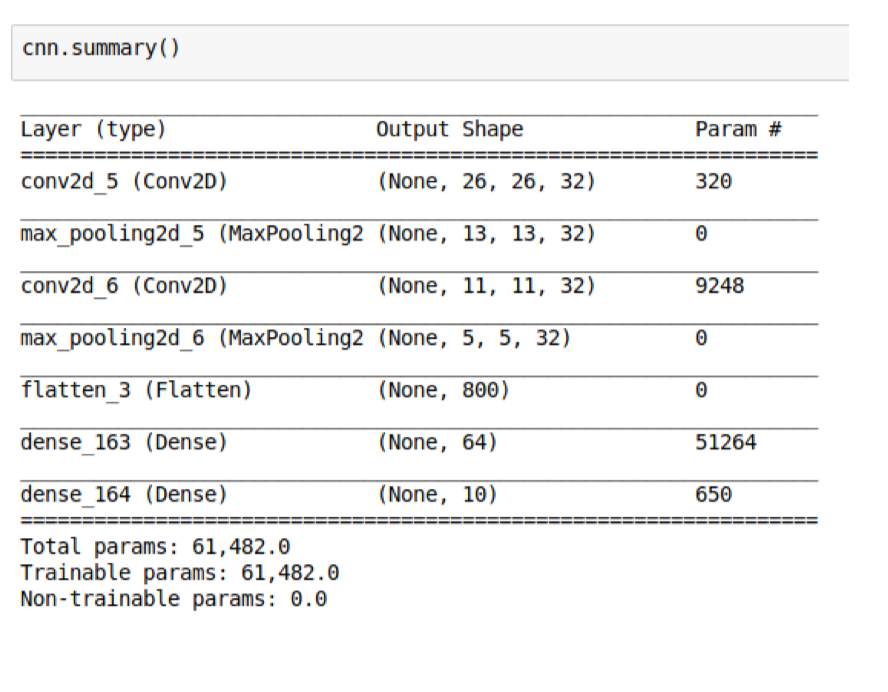
Calculate number of parameters in neural network
It’s really nothing fancy. For vanilla neural network, to calculate number of parameters in one layer, it is # of input \(\times\) # of output + # of output (for bias). It will be a bit trickier for convolutional neural network, where you need to take the kernel size into account: width \(\times\) height \(\times\) depth (number of filters we would like to use) \(\times\) (kernel size (including channel!) + 1 (for bias)) (Without parameter sharing).
Keras
Keras is an open source neural network library written in Python. It is capable of running on top of Tensorflow or Theano. The API is pretty straightforward (at least the sequencial one). Sequential provides a way to specify feed-forward neural network, one layer after another.
Note
For the first layer we need to specify the input shape so the model knows the sizes of all the matrices. The following layers can infer the sizes from the previous layers.
The process is:
Specifying the model (using a list or .add)
model.compile, with optimizer, loss, metrics, validation_split etc. specified.
Do model.fit, where the training starts
Evaluate on test set by model.evaluate(X,y,verbose=0), returns loss and accuracy as a tuple.
Necessary preparation
Flatten the data to (num_sample, num_params) (or reshape the data to either (num_samples, width, height, channel) or (num_samples, channel, width, height)), but don’t mess up with the dimension when doing convolutional neural net with images! (meaning when you reshape, you cannot brute force – you should roll/swap the axes and make sure after the reshaping, the image preserves.
Standardize so the model will become more stable and is much easier to train when the input is small numbers. Make sure you change to float before the standarization!!! Otherwise you will get all zeros because of the integer division in Python 2… (say this with tears)
Do keras.utils.to_categorical(y_train, num_classes) to do “one-hot” encoding for y.
Batch size is not a hyperparameters. Instead of gridsearching over it, keep increasing the batch size until you see above 90% GPU utilization.
Number of epochs can be tuned by manual tuning, early stopping, or callback.
Epochs is fit parameter, not in make_model.
Code
Use callable to wrap the keras and send it to keras classifier:
fromkeras.wrappers.scikit_learnimportKerasClassifierfromsklearn.model_selectionimportGridSearchCVdefmake_model(optimizer="adam",hidden_size=32):model=Sequential([Dense(hidden_size,input_shape=(784,)),Activation('relu'),Dense(10),Activation('softmax'),])model.compile(optimizer=optimizer,loss="categorical_crossentropy",metrics=['accuracy'])returnmodelclf=KerasClassifier(make_model)param_grid={'epochs':[1,5,10],# epochs is fit parameter, not in make_model!
'hidden_size':[32,64,256]}grid=GridSearchCV(clf,param_grid=param_grid,cv=5)
Drop-out regularization
We set some nodes to 0. And not only on the input layer, also the intermediate layer. For each sample, and each iteration we pick different nodes. Randomization avoids overfitting to particular examples.
Rate is often as high as 50%. When predicting, use all weights and down-weight by rate.
When to use drop-out:
Avoids overfitting
Allows using much deeper and larger models
Slows down training somewhat
Wasn’t able to produce better results on MNIST (I don’t have a GPU) but should be possible
High level idea: Convolutional Neural Network extends from vanilla neural net by exploiting the fact that input like images has archiecture: an image can be represented as a 3D volume (width, height, depth/channels) and therefore, instead of flattening them and losing this information, each layer of Convolutional Neural Net transforms an input 3D volume to an output 3D volume with some differentiable function that may or may not have parameters. That’s why it can do really powerful thing with much less parameters.
We can compute the spatial size of the output volume as a function of the input volume size (W), the receptive field size of the Conv Layer neurons (F), the stride with which they are applied (S), and the amount of zero padding used (P) on the border. You can convince yourself that the correct formula for calculating how many neurons “fit” is given by (W−F+2P)/S+1(W−F+2P)/S+1.
Parameter Sharing
Parameter sharing constrains the neurons in each depth slice (each filter) to use the same weights and bias. Now we only have num of filters \(\times\) (kernel_size (including channel) + 1 (for bias)). Note that the kernel size in the intermediate layer has a depth dimension as # of neurons in the previous layer.
Sanity Check Time: Why the second conv layer has 9248 parameters?
Max pooling
Max pooling is added to progressively reduce the size of the representation to reduce the amount of parameters and computation time. It can also control overfitting.
Sanity check time: A 2x2 max pooling layer gets rid of how many neurons?
Note: Need to remember position of maximum for back-propagation. Again not differentiable so needs to use subgradient descent.
Batch Normalization
Idea: neural networks learn best when the input is zero mean and unit variance. So let’s scale our data – even in the middle
Batch normalization re-normalizes the activations for a layer for each batch during training (as the distribution over activation changes). This happens before applying to activation function (so use BN between the linear and non-linear layers in your network).
Additional scale and shift parameters are learned that are applied after the per-batch normalization.
Use pre-trained networks
Idea: Utilize what people have done with a lot of datasets (“stood on the shoulders of giants”) as feature extraction / as initialization for fine tuning. Usually we will train a last “layer” on top of that, either being logistic regression or a MLP. Also called transfer learning.
Fine tuning: starting with pre-trained net, we back-propagate error through all layers “tune” filters to new data.
Note: This potentially doesn’t work with images from a very different domain, like medical images.
Definition: Adverserial samples are samples that were created by an adversary or attacker to fool your model. Usually they learnt the weights in their neural net and cheat by changing the picture slightly. It looks all the same to us, but the neural net will have totally different output.
Given how high-dimensional the input space is, this is not very surprising from a mathematical perspective, but it might be somewhat unexpected.
Time Series
Time Series differs from other data in the sense that it is not iid. (identically and independently distributed). There are equally spaced (like stocks) and non equally spaced (like earthquake data) time series.
Key point: the train/test split and validation set split is different as usual. We must make sure the training data set is in the past and we use those to predict future!
Tasks
1D forecasting: one thing, use past predict future
ND forecasting: multiple things, use past predict future (predict one or more)
Feature-based forecasting
Time series classification
Parse date & Time Series Index
The code will combine multiple columns into a single date (so concatenate years, months and days to a date. Furthermore, it treats the newly created column as the index – now pandas will be able to do stuff because this data frame is a time series data frame!
resampled_co2=manualoa.co2.resample("MS")# MS is month start frequency
resampled_co2.mean().head()# resampling is lazy -- only until when you use it, it will actually extract out the data
Detrending (look at differencing)
data.diff().plot()
Autocorrelation (correlation between two data point)
]]>Alan Duanduanyanl97@gmail.comMy Review Note for Applied Machine Learning (First Half)2017-03-07T00:00:00+00:002017-03-07T00:00:00+00:00https://yanlin-duan.github.io/machine%20learning/cheatsheetappliedML
Why this post
This semester I am taking Applied Machine Learning with Andreas Mueller. It’s a great class focusing on the practical side of machine learning.
As the midterm is coming, I am revising for what we have covered so far, and think that preparing a review note would be an effective way to do so (though the exam is closed book). I am posting my notes here so it can benefit more people.
Supplemental material of An Introduction to Machine Learning with Python by Andreas C. Müller and Sarah Guido (O’Reilly). Copyright 2017 Sarah Guido and Andreas Müller, 978-1-449-36941-5.
Care has been taken to avoid copyrighted contents as much as possible, and give citation wherever is proper.
Reinforcement Learning (explore & learn from the environment)
Others (semi-supervised, active learning, forecasting, etc.)
Parametric and Non-parametric models
Parametric model: Number of “parameters” (degrees of freedom) independent of data.
e.g.: Linear Regression, Logistic Regression, Nearest Shrunken Centroid
Non-parametric model: Degrees of freedom increase with more data. Each training instance can be viewed as a “parameter” in the model, as you use them in the prediction.
e.g.: Random Forest, Nearest Neighbors
Classification: From binary to multi-class
One v.s. Rest (OvR) (standard): needs n binary classifiers; predict the class with highest score.
One v.s. One (OvO): needs \(n \cdot (n-1) / 2\) binary classifiers; predict by voting for highest positives
How to formalize a machine learning problem in general
We want to find the \(f\) in function family \(F\) that minimizes the error (risk, denoted by function \(L\)) on the training set, and at the same time keeps it simple (denoted by the regularized term \(R\) and \(\alpha\)).
Decomposing Generalization Error (Bottou et. al, picture from Applied ML course note aml-06, page 28 & 29)
Difference between Machine Learning and Statistics
Data Leakage is the creation of unexpected additional information in the training data, allowing a model or machine learning algorithm to make unrealistically good predictions. Leakage is a pervasive challenge in applied machine learning, causing models to over-represent their generalization error and often rendering them useless in the real world. It can caused by human or mechanical error, and can be intentional or unintentional in both cases.
Source: https://www.kaggle.com/wiki/Leakage
Common mistakes include:
Keep features that are not available in new data
Leaking of information from the future into the past
Do preprocessing on the whole dataset (before train/test split)
Test on test data sets multiple times
Git
For git, I have found the following 2 YouTube videos very helpful:
The following slide by Andreas Mueller is also a very good one (which explains git reset, git revert, etc. which I did not cover in this note:
git init # use git to track current directoryrm .git # undo the above (your files are still there)
Typical workflow:
git clone [url] # clone a remote repository
git branch newBranch # create a new branch
git checkout newBranch # say "Now I want to work on that branch"# do your job...
git add this_file # add it to staging area
git commit # Take a snapshot of the state of the folder, with a commit message. It will be identified with an ID (hash value)
git push origin master # push from local -> remote
git pull origin master # pull from remote -> local
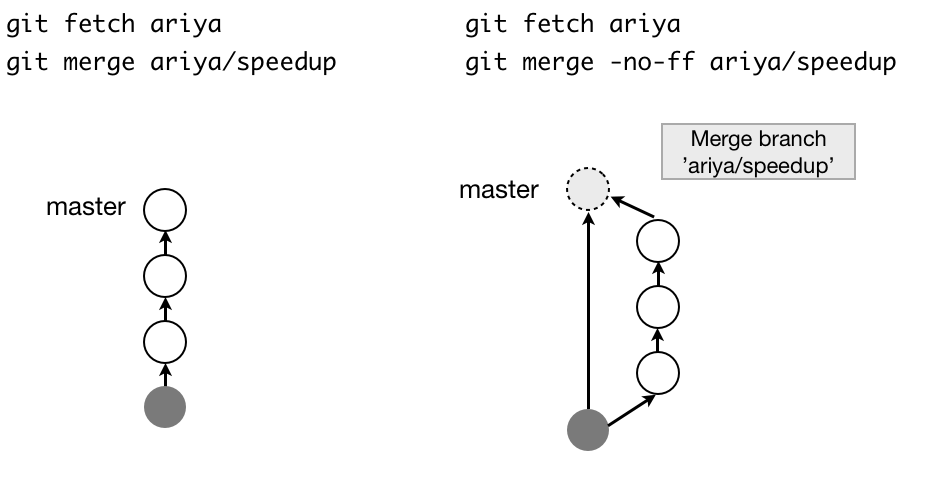
git merge A # merge branch A to current branch
My favorite shortcuts/commands:
git checkout -b newBranch # create branch and checkout in one line
git add -A# update the indices for all files in the entire working tree
git commit -a# stage files that have been modified and deleted, but not new files you have not done git add with
git commit -m <msg> # use the given <msg> as the commit message.
git stash # saves your local modifications away and reverts the working directory to match the HEAD commit. Can be used before a git pull
Note that git add -A and git commit -a may accidentally commit things you do not intend to, so use them with caution!
Other important ones (in lecture notes or used in Homework 1):
git reset --soft <commit> # moves HEAD to <commit>, takes the current branch with it
git reset --mixed <commit> # moves HEAD to <commit>, changes index to be at <commit>, but not working directory
git reset --hard <commit> # moved HEAD to <commit>, changes index and working tree to <commit>
git rebase -i <commit> # interactive rebase
git rebase --onto feature master~3 master # rebase everything from master~2 (master - 3 commits, excluding this one) up until the tip of master (included) to the tip of feature.
git reflog show # show reference logs that records when the tips of branches and other references were updated in the local repository.
git checkout HEAD@{3}# checkout to the commit where HEAD used to be three moves ago
git checkout feature this_file # merge the specific file (this_file) from feature to your current branch
git log # show git log
The hardest part of git in my opinion is the “polymorphism” of git commands. As shown above, you can do git checkout on a branch, a commit, a commit + a file, and they all mean different things. (This motivates me to write a git tutorial in the future when I have time, where I will go through the common git commands in a different way as existing tutorials.)
Difference (Relationship) between git and github: people new to git may be confused by those two. In one sentence: Git is a version control tool, and GitHub is an online project hosting platform using git.(Therefore, you may use git with or without Github.)
Pull requests allow you to contribute to a repository which you don’t have permission to write to. The general workflow is: fork -> clone to local -> add a feature branch -> make changes -> push.
To keep update with the upstream, you may also need to: add upstream as another remote -> pull from upstream -> work upon it -> push to your origin remote.
Interpreted language: slow (many libraries written in C/Fortran/Cython)
Python 2 v.s. Python 3 (main changes in: division, print, iterator, string; need something from python 3 in python 2? do from __future__ import bla)
For good practices, always use explicit imports and standard naming
conventions. (Don’t from bla import *!)
Testing and Documentation:
Different kinds of tests
Unit Tests: a function is doing the right thing; Can be done with pytest
Integration tests: functions together are doing the right thing; Can be done with TravisCI (continuous integration)
Non-regression tests: bugs truly get removed
Different ways of doing documentation:
PEP 257 for docstrings and inline comments
NumpyDoc format
Various tools for generating documentation pages: SPhinx, ReadTheDocs
Visualization – Exploration and Communications
Visual Channels: Try not to…
Use 3D-volume to show information
Use textures to show information
Use hues for quantitative changes
Use bad colormaps such as jet and rainbow. They vary non-linearly and non-monotonically in lightness, which can create edges in images where there are none. The varying lightness also makes grayscale print completely useless.
Color maps:
Sequential Colormaps
Diverging Colormaps
Qualitative Colormaps
Miscellaneous Colormaps
Go from one hue/saturation to another (Lightness also changes)
Grey/white (focus point) in the middle, different hues going in either direction
Use to show discrete values
Don’t use jet and rainbow! (Andy will be disappointed if you do so @.@)
Use to emphasize extremes
Use to show deviation from the neutral points
Designed to have optimum contrast for a particular number of discrete values
Use perceptual uniform colormaps
Matplotlib Quick Intro:
% matplotlib inline v.s. % matplotlib notebook in Jupyter Notebook
Figure and Axes:
Create automatically by doing plot command
Create by plt.figure()
Create by plt.subplots(n,m)
Create by plt.subplot(n, m, i), where i is 1-indexed, column-based position
Two interfaces:
Stateful interface: applies to current figure and axes (e.g.: plt.xlim)
Object-oriented interface: explicitly use object (e.g.: ax.set_xlim)
Important commands:
Plot command ax.plot(np.linspace(-4, 4, 100), sin, '--o', c = 'r', lw = 3)
Use figsize to specify how large each plot is (otherwise it will be “squeezed”)
Single variable x: plot it against its index; Two variables x and y: plot against each other
By default, it’s line-plot. Use “o” to create a scatterplot
Can change the width, color, dashing and markers of the plot
Scatter command: ax.scatter(x, y, c=x-y, s=np.abs(np.random.normal(scale=20, size=50)), cmap='bwr', edgecolor='k')
We lose a lot of data for evaluation, and the results depend on the particular sampling. (overfit on validation set)
Third Attempt: K-fold Cross Validation + Train/Test split
Idea
Split data into multiple folds and built multiple models. Each time test models on different (unused) fold.
Code
fromsklearn.model_selectionimportcross_val_scorescores=cross_val_score(knn,X_trainval,y_trainval,cv=10)# equiv to StratifiedKFold without shuffle
print(np.mean(scores),np.std(scores))
Pros
Each data point is in the test-set exactly once.
Better data use (larger training sets)
Cons
It takes 5 or 10 times longer (you train 5/10 models)
Stratified K-Fold: preserves the class frequencies in each fold to be the same as of the overall dataset
Especially helpful when data is imbalanced
Leave One Out: Equivalent to KFold(n_folds=n_samples), where we use n-1 samples to train and 1 to test.
Cons: high variance, and it takes a long time!
Solution: Repeated (Stratified) K-Fold + Shuffling: Reduces variance, so better!
ShuffleSplit: Repeatedly and randomly pick training/test sets based on training/test set size for number of iterations times.
Pros: Especially good for subsample when data set is large
GroupKFold: Patient example; where samples in the same group are highly correlated. New data essentially means new group. So we want to split data based on group.
TimeSeriesSplit: Stock price example; Taking increasing chunks of data from the past and making predictions on the next chunk. Making sure you do not have access to the “future”.
Final Attempt 1: Use GridSearch CV that wraps up everything
Code
fromsklearn.model_selectionimportGridSearchCVX_train,X_test,y_train,y_test=train_test_split(X,y,stratify=y)param_grid={'n_neighbors':np.arange(1,20,3)}grid=GridSearchCV(KNeighborsClassifier(),param_grid=param_grid,cv=10)grid.fit(X_train,y_train)print(grid.best_score_,grid.best_params_)#grid also has grid.cv_results_ which has many useful statistics
Note
We still need to split our data into training and test set.
If we do GridSearchCV on a pipeline, the param_grid’s key should look like: 'svc__C:'.
Final Attempt 2: Use built-in CV for specific models
We also have RFECV (efficient cv for recursive feature elimination) and CalibratedClassifierCV (Cross validation for calibration)
All have reasonable built-in parameter grids.
For RidgeCV you can’t pick the “cv”!
Preprocessing
Dealing with missing data: Imputation
In real life it’s very common that the data set is not clean. There are missing values in it. We need to fill them in before training model using it.
Imputaion methods
Mean/median
KNN: find k nearest neighbors that have non-missing values and average their values; tricky if there is no feature that is always non-missing. (we need such to find nearest neighbors)
Model driven: Train regression model for missing values, can also do this iteratively. Very flexible methods
Iterative
fancyimpute: Has many methods; MICE (Reimplementation of Multiple Imputation by Chained Equations), more details here
Code
fromsklearn.preprocessingimportImputerimp=Imputer(strategy="mean").fit(X_train)X_mean_imp=imp.transform(X_train)# Use of fancyimpute
importfancyimputeX_train_fancy_knn=fancyimpute.KNN().complete(X_train)
Scaling and Centering
When to scale & centering
The following model examples are particularly sensitive on scale of features:
KNN
Linear Models
When not to scale
The following model(s) is(are) not quite sensitive to scaling:
Decision Tree
If data is sparse, do not center (make data dense). Only scale is fine.
How to scale
StandardScaler: subtract mean and divide by standard
deviation.
MinMaxScaler: subtract minimum, divide by (max - min), resulting in range 0 and 1.
Robust Scaler: uses median and quantiles, therefore robust to outliers. Similar to StandardScaler.
Normalizer: only considers angle, not length. Helpful for histograms, not that often used.
We should perform scaler.fit only on training data!
Pipelines
Pipelines are used to solve the common need of linking preprocessing, models, etc. together and prevents information leakage.
Code
fromsklearn.pipelineimportmake_pipelinepipe=make_pipeline(StandardScaler(),Lasso())pipe.fit(X_train,y_train)pipe.score(X_test,y_test)print(pipe.steps)# Or we can have pipeline with named steps
fromsklearn.pipelineimportPipelinepipe=Pipeline((("scaler",StandardScaler()),("regressor",KNeighborsRegressor)))# Note how param_grid change when combining GridSearchCV with pipeline
fromsklearn.model_selectionimportGridSearchCVpipe=make_pipeline(StandardScaler(),SVC())param_grid={'svc__C':range(1,20)}grid=GridSearchCV(pipe,param_grid,cv=10)grid.fit(X_train,y_train)score=grid.score(X_test,y_test)
Feature Transformation
Why do feature transformation
Linear models and neural networks, for example, perform better when the features are approximately normal distributed.
Box-Cox Transformation
Box-Cox minimizes skew, trying to create a more “Gaussian-looking” distribution.
Box-Cox only works on positive features!
Code
fromscipyimportstatsfromsklearn.preprocessingimportMinMaxScalerX_train_mm=MinMaxScaler().fit_transform(X_train)# Use MinMaxScaler to make all features positive
X_bc=[]foriinrange(X_train_mm.shape[1]):X_bc.append(stats.boxcox(X_train_mm[:,i]+1e-5))
Discrete/Categorical Features
Why it matters
It doesn’t make sense to train the model (esp linear model) directly if the data set contains discrete features, where “0,1,2” means nothing but different category.
Models that support discrete features
In theory, tree-based models do not care if you have categorical features. However, current scikit-learn implementation does not support discrete features in any of its models
One-hot Encoding (Turn k categories to k dummy variables)
importpandasaspdpd.get_dummies(df,columns=['boro'])# alternatively, specified by astype
df=pd.DataFrame({'year_built':[2006,1973,1988,1984,2010,1972],'boro':['Manhattan','Queens','Manhattan','Brooklyn','Brooklyn','Bronx']})df.boro=df.boro.astype("category",categories=['Manhattan','Queens','Brooklyn','Bronx','Staten Island'])pd.get_dummies(df)# or, we can use one-hot encoder in scikit-learn
fromsklearn.preprocessingimportOneHotEncoderdf=pd.DataFrame({'year_built':[2006,1973,1988,1984,2010,1972],'boro':[0,1,0,2,2,3]})OneHotEncoder(categorical_features=[0]).fit_transform(df.values).toarray()
Count-based Encoding
For high cardinality categorical features, instead of creating many dummy variables, we can create count-based new features based on it. For example, average response, likelihood, etc.
Feature Engineering and Feature Selection
Add polynomial features
Sometimes we want to add features to make our model stronger. One way is to add interactive features, i.e. polynomial features.
Build model, and select features that are most important to the model.
Can be done with SelectFromModel
Also can be implemented iteratively (Recursive Feature Elimination)
RFE can be called forward (if # of features required is small) or backwards
mlxtend package also implements a SequentialFeatureSelector
How is SequentialFeatureSelector different from Recursive Feature Elimination (RFE)
RFE is computationally less complex using the feature weight coefficients (e.g., linear models) or feature importance (tree-based algorithms) to eliminate features recursively, whereas SFSs eliminate (or add) features based on a user-defined classifier/regression performance metric.
Difference between Nearest Shrunken Centroid and Nearest Centroid 6
It “shrinks” each of the class centroids toward the overall centroid for all classes by an amount we call the threshold . This shrinkage consists of moving the centroid towards zero by threshold, setting it equal to zero if it hits zero. For example if threshold was 2.0, a centroid of 3.2 would be shrunk to 1.2, a centroid of -3.4 would be shrunk to -1.4, and a centroid of 1.2 would be shrunk to zero.
fromsklearn.linear_modelimportRidgeridge=Ridge(alpha=10).fit(X_train,y_train)# takes alpha as a parameter
print(ridge.coef_)#can get coefficients this way
Iteratively train a model and at the same time, detect outliers.
It is non-deterministic in the sense that it produces a reasonable result only with a certain probability. The more iterations allowed, the high the probability.
Minimizes what is called “Huber Loss”, which makes sure that the loss function is not heavily affected by the outliers. At the same time, it will not completely ignore their influence.
The higher C, the less regularization. (inverse to \(\alpha\))
l2-norm version is smooth (differentiable)
l1-norm version gives sparse solution / more compact model
Logistic regression gives probability estimates
In multi-class case, using OvR by default
Solver: ‘liblinear’ for small datasets, ‘sag’ for large datasets and if you want speed; only ‘newton-cg’, ‘sag’ and ‘lbfgs’ handle multinomial loss; ‘liblinear’ is limited to one-versus-rest schemes; ‘newton-cg’, ‘lbfgs’ and ‘sag’ only handle L2 penalty. More details here
Use Stochastic Average Gradient Descent solver for really large n_samples
Code
fromsklearn.linear_modelimportLogisticRegressionlogreg=LogisticRegression()logreg=LogisticRegression(multi_class="multinomial",solver="lbfgs").fit(X,y)# multi-class version
logreg.fit(X_train,y_train)
Both versions are strongly convex, but neither is smooth
Only some points contribute (the support vectors). So the solution is naturally sparse
There’s no probability estimate. (Though we have SVC(probability=True)?)
Use LinearSVC if we want a linear SVM instead of SVC(kernel="linear")
Prefer dual=False when n_samples > n_features.
Lars / LassoLars
Model
It is Lasso model fit with Least Angle Regression a.k.a. Lars. More details here
Note
Use when n_features » n_samples
Model: Support Vector Machine (Kernelized SVM)
Sometimes we want models stronger than a linear decision boundary. At the same time, we want the optimization problem to be “easily” solvable, i.e. making sure it is convex.
One way to achieve this is by adding polynomial features. This raises the dataset to higher dimension, resulting a non-linear decision boundary in the original space. The drawback of this is the computational cost and storage cost. After adding interactive features, the feature space becomes much higher, and we need more time to train the model, predict the model and more space for storage.
Kernel SVM, in some sense, solves this problem. On one hand, we can enjoy the benefit of high dimensionality; On the other hand, we do not need to do computation in that high dimensional space. This magic is done by the kernel function.
Duality and Kernel Function
Optimization theory tells us that the SVM problem can also be viewed as :
Now, if we have a function \(\phi\) that maps our feature space from some low dimension \(d\) to high dimension \(D\). In SVM dual problem, we then need to calculate the dot product:
We don’t want to explicitly have \(\phi(x)\) calculated in a high dimension \(D\). After all, all we care is the result of the dot product. We want to do some calculations in low dimension \(d\), and somehow, a magic function \(k(x_i, x_j)\) would give us the dot product.
Thankfully, Mercer’s theorem tells us that as long as k is a symmetric, and positive definite, there exists a corresponding \(\phi\)!
Trees are popular non-linear machine learning models, largely because of its power, flexibility and interpretability.
Decision Tree
Decision trees are commonly used for classification. The idea is to partition the data to different classes by asking a series of (true/false) questions. Compared to models like KNN, trees are much faster in terms of prediction.
Another good thing about decision trees is that it can work on categorical data directly (no encoding needed).
Criteria:
For classification:
Gini index
Cross-entropy
For regression:
Mean Absolute Error
Mean Squared Error
For Bagging Models:
Out-Of-Bag error (the mean prediction error on each training sample \(x_i\), using only the trees that did not have \(x_i\) in their bootstrap sample)
Visualization
Use graphviz library
Avoid Overfitting
To avoid overfitting, we usually tune (through GridSearchCV!) one of the following parameters (they all in some sense reduce the size of the tree):
max_depth (how deep is the tree)
max_leaf_nodes (how many ending states)
min_sample_split (at least split that amount of sample)
Note that if we prune, the leaf will not be so pure, so we will come to a state where we are “X% certain that some data should be class A”.
Ensemble method essentially means the wisdom of the crowd: meaning we train a bunch of weak classifiers and let them correct each other.
Common applications include Voting Classifier, Bagging and Random Forest
Voting Classifier – Majority rule Classifier
Soft voting classifier: each classifier calculates class probability
Hard voting classifier: each classifier directly outputs class label
fromsklearn.ensembleimportVotingClassifier# let a LinearSVC and a decision tree vote
voting=VotingClassifier([('svc',LinearSVC(C=100)),('tree',DecisionTreeClassifier(max_depth=3,random_state=0))],voting='hard')voting.fit(X_train,y_train)
Bagging (Bootstrap Aggregation)
Draw bootstrap samples (usually with replacement). So each time the data sets are a bit different, so the model will also be slightly different.
Random Forest – Bagging of Decision Trees
For each tree, we randomly pick bootstrap samples
For each split, we randomly pick features
Choose max_features to be \(\sqrt{\text{n_features}}\) for classification and around n_features for regression
May use warm start to accelerate/ get better performance
The key idea of stacking is that we believe different types of models can learn some part of the problems, but maybe not the whole problem. So let us build multiple learners and learn their parts, and use their outputs as the intermediate prediction. Then we use that intermediate prediction as the input to another second-step learner (so called “stacked on the top”), and finally get the output.
When doing classification, we usually need to pickle a threshold for the model. By default, the threshold is 90%, meaning if the model is more than 50% certain that this is in class A, we should classify it as such.
However, models may be wrong. For example, if we do not prune, the decision tree’s leaf will be pure, meaning that the model is 100% sure that every data in this state should be in some class. This is largely untrue. Therefore, we need to calibrate the model: letting the model provide a correct measurement of uncertainty.
The usual way to do calibration that is to build another (1D) model that takes the classifier probability and predicts a better probability, hopefully similar to \(p(y)\).
Platt scaling: \(f_{\text{platt}} = \frac{1}{1 + \exp(-s(x))}\) is one way. Essentially it is equivalent to train a 1d logistic regression.
Isotonic Ression is another way. It finds a non-decreasing approximation of a function while minimizing the mean squared error on the training data.
Data to use: Either use hold-out set or cross-validation
Function to use: CalibratedClassifierCV
fromsklearn.calibrationimportCalibratedClassifierCV# first, train some random forest classifier
rf=RandomForestClassifier(n_estimators=200).fit(X_train_sub,y_train_sub)# then, we use calibrated classifier cv on it
cal_rf=CalibratedClassifierCV(rf,cv="prefit",method='sigmoid')cal_rf.fit(X_val,y_val)print(cal_rf.predict_proba(X_test)[:,1])
When to use tree-based models
When you want non-linear Relationship
When you want interpretable result (go with 1 tree)
When you want best performance (Gradient boosting is the common model for winners of Kaggle competition)
Many categorical data / Don’t want to do feature engineering
In principle we don’t care too much about performance on training data, but on new samples from the same distribution. ↩
]]>Alan Duanduanyanl97@gmail.comWhy learning Operating System with Linux Arch?2017-02-03T00:00:00+00:002017-02-03T00:00:00+00:00https://yanlin-duan.github.io/operating%20system/archbeginningMy first attempt of learning Linux and Operating System
This semester at Columbia, I am taking operating system class with Prof. Jae Woo Lee (I usually call him Jae, as this is also how most students would refer him to).
The class just began and we haven’t gone to the most exciting (desperate?) part of implementing parts of the kernel. Since I still have time to take a breathe and make sure I am ready for the following weeks of ‘hacking’, I decide to sit down, play with the virtual machine we will be using for development, and customize it in a way that will make me very very efficient later on.
The first big question: why Arch
So I know we are learning operating system, and by saying that in most schools I think it means to learn the operating system theories plus hand-on experience with Linux. Undoubtedly, Linux is a free, open-source masterpiece. However, given all those Linux distributions (a Linux distribution basically means an OS with Linux Kernel + package management software + this and that), with some famous name to beginners like me (Ubuntu, Redhat), what makes Arch a great choice for OS learners – To be honest, I never knew about Arch back to 30 days before!
I think it is very important to know ‘why’ behind instead of blindly following the instructions from professor / online. Only after understanding the rationale behind can I fully appreciate the convenience and the greatness of the tool.
It took me some Googling and Googoogling (meaning Google whatever I Googled, a depth-2 search) to find 3 most important reasons. As I am still new to this, this post is mostly a summarization. I will update more later after I get more hands-on experiences and have more say about this.
The first and foremost: Really good wiki pages
Okay this may not sound like a killer feature of this distribution, but trust me it is. Usually when people don’t get into trouble, long, detailed Wiki pages are considered as verbose and boring. But when it comes to a place where you need to hack, break and fix things, you will actually want some guidance, and more, and more. For example, Arch installation is such a pain (comparatively), but it is compensated with a very good installation guide here. For a learner, nothing is better than good documentation. It is your last resort, after google, stackoverflow and ask people in the dev community.
Light-weight, yet highly customizable
I read about the principle of Arch, one of them being “Simplicity”. As someone who had experience with pirated Windows XP, I understand the feeling when your OS comes with something that you don’t need, but you cannot fully uninstall them. So Arch features being small and only contains those must-have, and leaves the rest for users to install based on their needs. Again this is great for OS learners because first-of-all, you don’t want your virtual box to take up your entire hard disk, and at the same time, you want to have all the necessary tools for development. It is also a great learning experience to install, configure those tools.
Pacman + AUR
Speaking of tools, I saw many comments online about the pacman package management system that Arch adopts. I do not have prior experience in shipping packages, but I did use homebrew and apt-get for some time. So one of the general comments I heard about is that pacman, being a binary repository management, is more modern in terms of its software architecture. It allows this C program to achieve its core functionality nicely. Also it is said that pacman’s command deign is more user friendly. That means, all the commands are more standardized. They all look like pacman [Some Main Action] [Flags] target. Last but not least, pacman -Syu is a one-line command that helps you update your system. This sounds pretty cool! In addition, many recommend yaourt as a front-end for pacman. I will definitely have a try!
At the same time, the community-driven Arch User Repository (AUR) seems to be another big reason why people choose Arch. It contains extensive repositories that users uploaded. As mentioned in Arch Wiki:
Debian is the largest upstream Linux distribution with a bigger community and features stable, testing, and unstable branches, offering over 43,000 packages. The available number of Arch binary packages is more modest. However, when including the AUR, the quantities are comparable.
Now Arch seems to be a pretty fun OS to learn and play with. Let me come back later with more personal sharing. Stay tuned!
]]>Alan Duanduanyanl97@gmail.comUsing mathjax on GitHub Pages with Jekyll2017-02-01T00:00:00+00:002017-02-01T00:00:00+00:00https://yanlin-duan.github.io/random/mathjaxWhy this post
As I realize that I need to write a bunch of math formulas in my blog, I am searching for a way to write \(\LaTeX\) in Markdown and then render that in HTML. Mathjax jumps on my browser when I search on Google. However, when I try to integrate it with Jekyll (specifically, GitHub pages), I ran into errors after following many (top-ranked) stackoverflow / official doc instructions.
What do you need to do – Simple 4 Steps
Disclaimer:
The following guide has been proved to work on GitHub Pages using Jekyll. The theme you use should not affect anything, but I can only say for Minimal Mistakes (the theme I chose to use) everything works perfectly.
Note that It may (and will!) be different if you use other blog frameworks (e.g. Hexo) or are hosting your sites on other platforms.
In your _config.yml, stick with kramdown. Some instructions may tell you to go with maruku or redcarpet. Don’t. Those instructions are either outdated or do not fit GitHub Pages. Keep using kramdown by making sure there is no markdown: xxx (xxx is something other than kramdown; it is also okay if you don’t have this line as it is by default kramdown) in your _config.yml. kramdown is the only Markdown engine GitHub Pages officially supports right now.
This step is sort of theme dependent: If you have _include folder and there is either script.html or head.html there, you can add the following codes to one of those files. Otherwise, you may go to _layouts and add the codes to default.html. Then your post / whatever sites that need mathjax should implicitly or explicitly be using the default layout.
{% if page.usemathjax %}
<script type="text/javascript"asyncsrc="https://cdn.mathjax.org/mathjax/latest/MathJax.js?config=TeX-MML-AM_CHTML"></script>
{% end if %}
Some sites may ask you to use the code from this source: http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=TeX-AMS-MML_HTMLorMML. This does not work for me, but is worth trying. (I think this somehow relates to AMS that is used for autoNumber but didn’t get it to work).
Then in the post / sites markdown file that you want to use mathjax, include the following in your YAML front matter (the table between three dash lines at the very beginning): usemathjax: true
This will set page.usemathjax to True when Jekyll use the liquid template to generate HTML, and thus adding the script to you page.
To use mathjax, simply write your \(\LaTeX\) codes between a double dollar-sign. Wahoo! That’s it! You are all set!






 三年前我拍的第一张CMU的照片 – CMU著名标志“送你上青天”
三年前我拍的第一张CMU的照片 – CMU著名标志“送你上青天” 15-112的Blue Hoodie
15-112的Blue Hoodie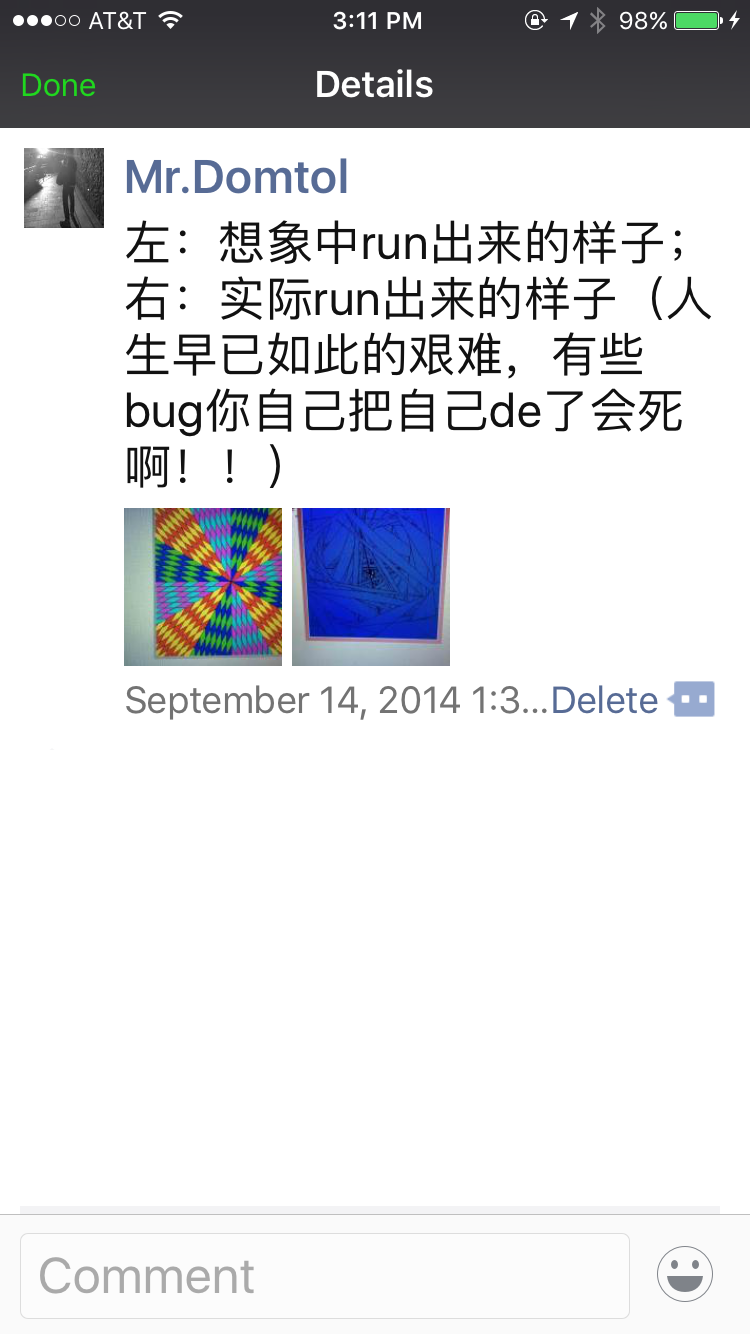 三年前疯狂Debug的我
三年前疯狂Debug的我 Dropbox食堂。图片来自于: https://goo.gl/Arzs2N
Dropbox食堂。图片来自于: https://goo.gl/Arzs2N Airbnb实习生活动之一:Magical Sailing
Airbnb实习生活动之一:Magical Sailing
 Prof. David Kosbie在2014年秋季学期的最后一封Piazza note
Prof. David Kosbie在2014年秋季学期的最后一封Piazza note Go Robinhood!
Go Robinhood!